Three Fixes for Running 30+ Claude Sessions in Parallel.
Three problems, the same shape — turn implicit, hard-to-see state into legible, queryable artifacts.
I run dozens of Claude Code sessions in parallel daily to ship my projects. After months of doing this, three things were dragging the workflow to a crawl: sessions stepping on each other; finding what I'd already decided last week; and getting a session to wake up when a client texted. All three have fixes now. This is what they are and how they work.
If you're running more than ten parallel sessions, you've probably hit at least one of these.
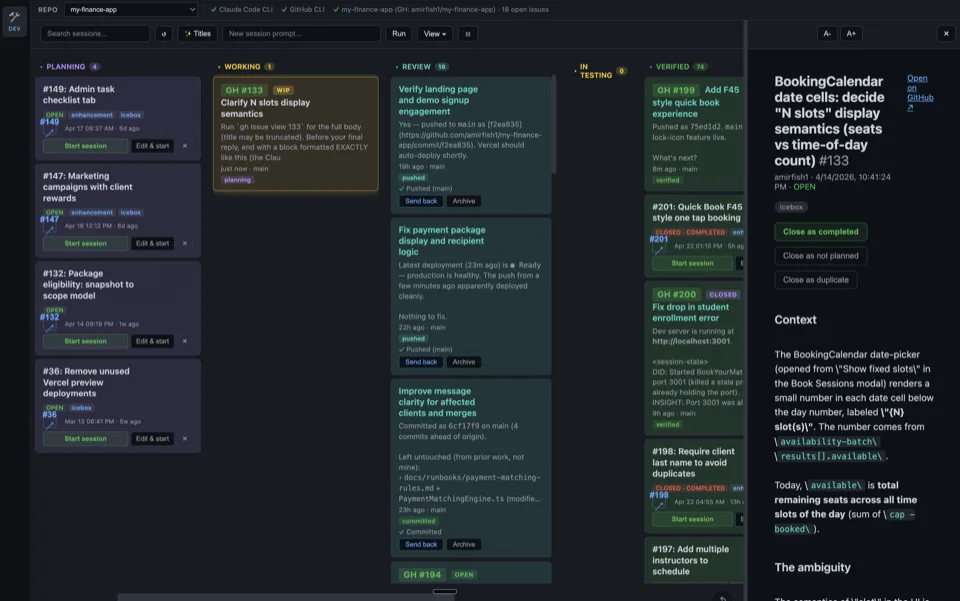
Putting Multiple Sessions in a Group Chat.
When you're running thirty Claude sessions at once, the bottleneck stops being any single agent's reasoning. It becomes coordination — getting sessions to know what other sessions are doing, defer to each other, ask for help, and not step on each other's work.
I started with a narrow version of this problem. Five sessions on the same main branch, each wanting to commit. They'd burn cycles checking git status, second-guessing whether files were theirs, sometimes clobbering each other anyway. The git index is a single shared file1 — between the moment one session runs git add and the moment it runs git commit, a sibling can stage their own work into the same index, and the commit picks up whatever is staged.
That was a real bug. I observed it bite twice in one day across two repos. So I built a fix for it: a shared markdown file the sessions read and write to, where each session announces what it's about to stage before staging.
What I didn't expect is how quickly the same mechanism became useful for everything else.
Here's what coordination thinking looks like in practice, mid-task — a session weighing whether to ship a small tweak now or wait for a sibling's larger PR to land first:
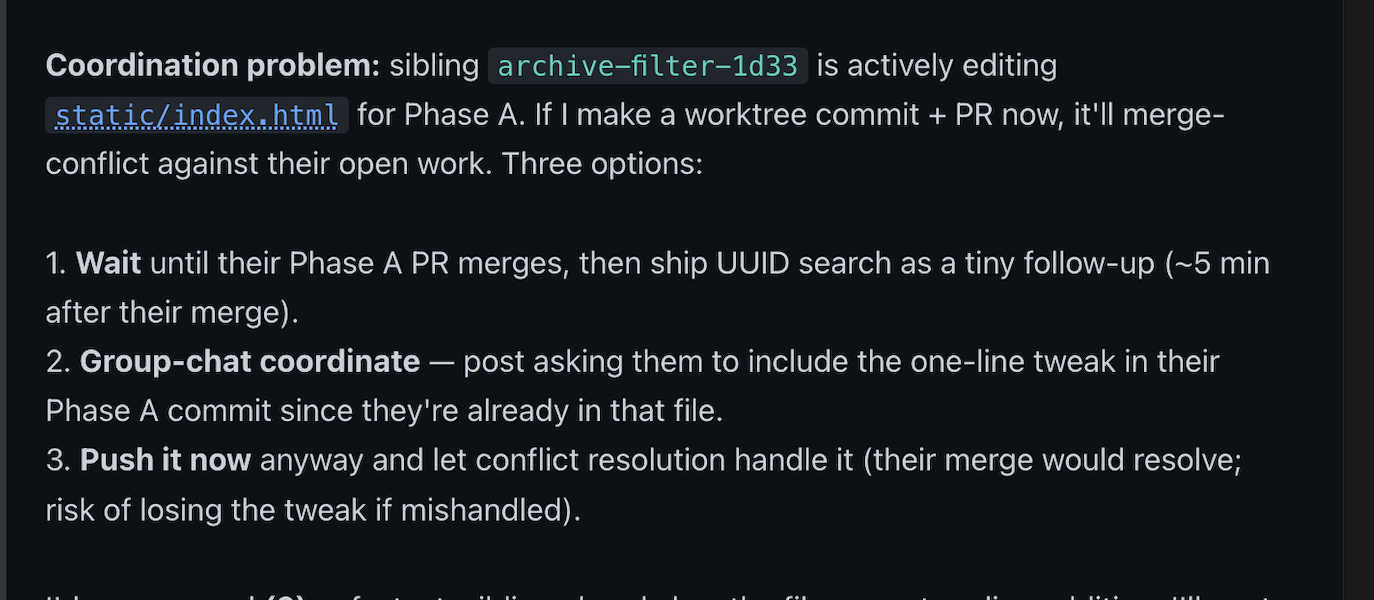
Before the chat existed, decisions like this were either silent — commit and hope — or noisy: interrupt the user, wait, restart. The chat doesn't eliminate the trade-off. It gives the trade-off a place to live, where another session can read it, weigh in, and reduce the deliberation to one line.
The pattern — sessions in a shared room.
The mental model is a group chat2 for autonomous workers. Each session signs with a tag (archive-filter-1d33, codex-spawn-7c25). When something needs coordination, any session can drop a message in the room — propose a sequence, ask for an ack, request a second opinion, raise a flag, hand off context. Other sessions read on entry, react if relevant, ignore if not.
Three coordination patterns I now use it for, every day:
- Staged commits. Before staging, post the paths you're touching. Siblings ack or counter. After committing, post the SHA. Combined with
git commit --only <paths>(atomic, race-free), the clobber problem disappears entirely. - Second opinions across context boundaries. When a session is deep in code and needs a sanity check, I tell it: "Drop this in the group chat — anyone who's been working in this area should weigh in." Sessions that have spent hours in adjacent code respond with the context the asking session doesn't have.
- Multi-session collaboration on one problem. When two or three sessions converge on a hard issue, I send them all to the chat: "Go on a group chat about this, agree on an approach, then one of you executes." They negotiate without me, post the resolution, and one takes the work.
The protocol underneath is intentionally minimal — sessions read the room, classify the state (open question, proposal, executing, done), and pick the action their role implies. There's a /group-chat slash-command skill that handles the role logic, but the underlying surface is just a markdown file. No daemon. No IPC. No central server.
What I learned: the mechanism wasn't really about commits. It was about making coordination legible. Once sessions had a place to be visible to each other, all sorts of useful things they couldn't previously do became possible.
An example — asking the right peer for context.
Working in CCC's own codebase one morning, I asked the session — read-only — whether history search used semantic embeddings. It looked at the code, found the answer, and surfaced it cleanly: history search is BM25-ranked FTS5 over a separate claude-index database, lexical only. No vector embeddings.
![A CCC session investigating its own history search code. First prompt: 'does history search use semantic search? [don't write anything - read-only mode]'. The session investigates and answers: 'No — history search is lexical, not semantic.' It cites server.py:12471 (search_conversation_history runs messages_fts MATCH ? with bm25 ordering), server.py:12350 header comment, and the lexical query rewriter. Concludes: keyword/phrase matching with BM25, no vector embeddings. Second prompt: 'can you check with the indexing session how to support semantic?' Tool use shown: 'Running List CCC sessions on 127.0.0.1' — the session looking up its peers via the registry.](/images/group-chat-consultation.png)
My next move was the give-away. Rather than building semantic search into CCC's code in this session — which had no claude-index context loaded — I asked: "can you check with the indexing session how to support semantic?" The session opened CCC's registry, found the indexing peer, and routed the question. Pattern two from the list above, made concrete: a session deep in code recognizes it doesn't have the right context, and instead of guessing, it asks the peer that does.
A side example — cross-session task delegation.
Same primitive, broader use. I had a long-running session on my machine called "my office manager" — it tracks tasks, reminders, and project state across all my work. One day a separate session needed to push something onto its agenda.
I didn't have to do it manually. I told the working session: "Find my office manager — make this its top priority." The session asked CCC for the list of open sessions on the machine, found the one named "my office manager," and used CCC's inject3 API to push a high-priority message into it. The office-manager session picked it up on its next turn.
Two sessions, neither one knowing about the other ahead of time, coordinated through a shared substrate. Any session can ask CCC who else is alive, what they're working on, and route work or questions to them.
Another example — routing bugs to the right peer.
I'd been running a Claude session against a Hebrew-speaking client's web app, talking with the client through a WhatsApp pipeline. The pipeline itself — Twilio webhook → Supabase Realtime → CCC inject — was built and shipped by a separate peer session, earlier the same morning. Worth pausing on this: the client-app session was the one that had spawned that peer, through a CCC orchestration call, with one specific job — go build the push-driven event bus that the client-app session needed.
So the daemon wasn't built by some random other Claude. It was built by infrastructure the client-app session had stood up itself. A session bootstrapping its own substrate.
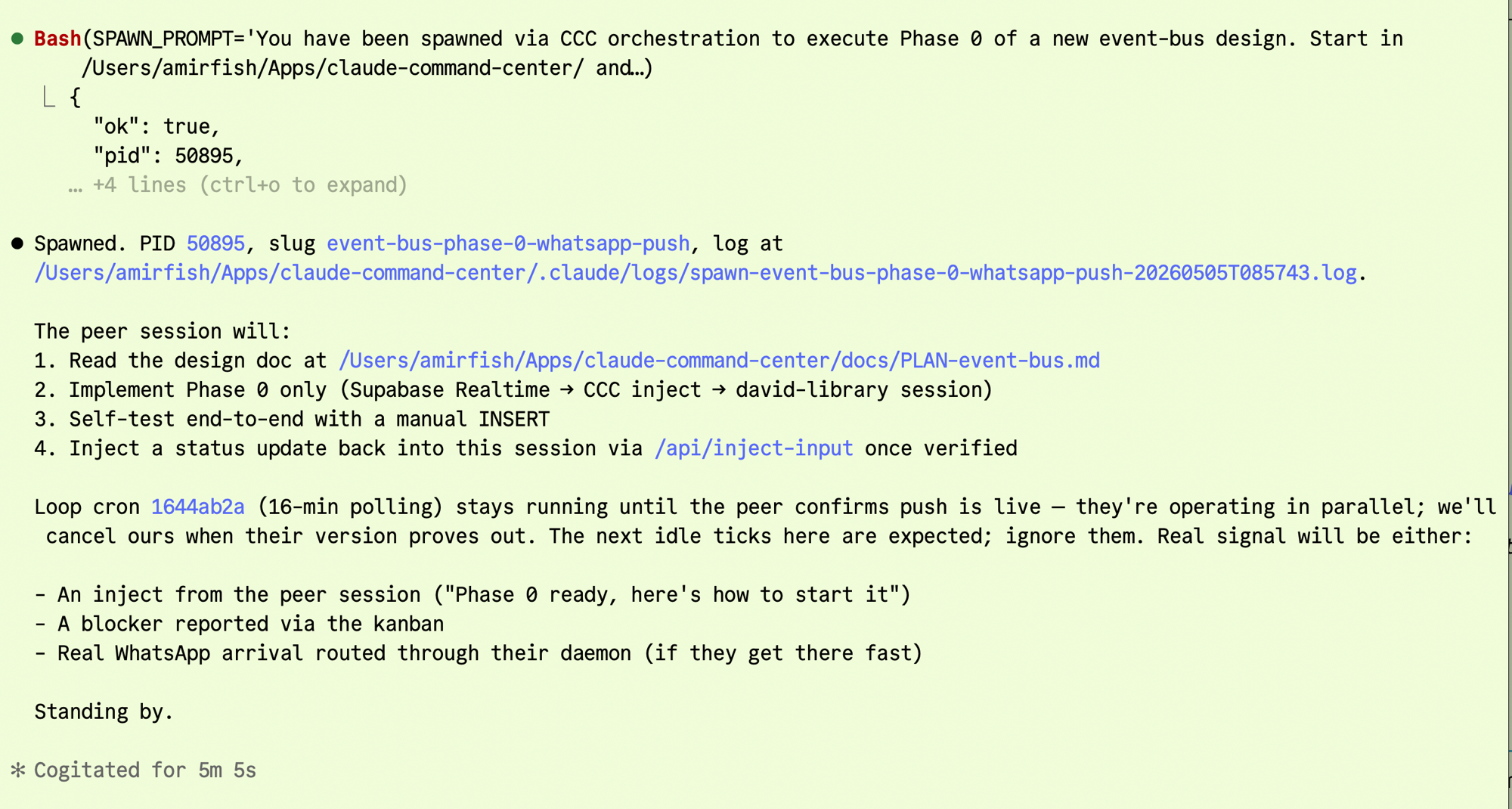
Mid-task, that client-app session noticed two production bugs in the daemon. It was the session being injected into, so it could see them clearly: every WhatsApp message produced two injects instead of one, and each inject landed in the terminal buffer but never pressed Enter, so its own input box quietly accumulated stale text.
It didn't try to fix the daemon itself. Fixing would have lost its own context — David was still waiting on a feature — and risked introducing new bugs in code it had never read. Instead, it pushed a triaged report directly to the peer that had built the daemon, via CCC's inject API. Priority-ordered hypotheses for each root cause, diagnostic steps to verify each one, and a suggested fix that referenced a sibling session's iMessage-inject pattern as the shape to mirror.
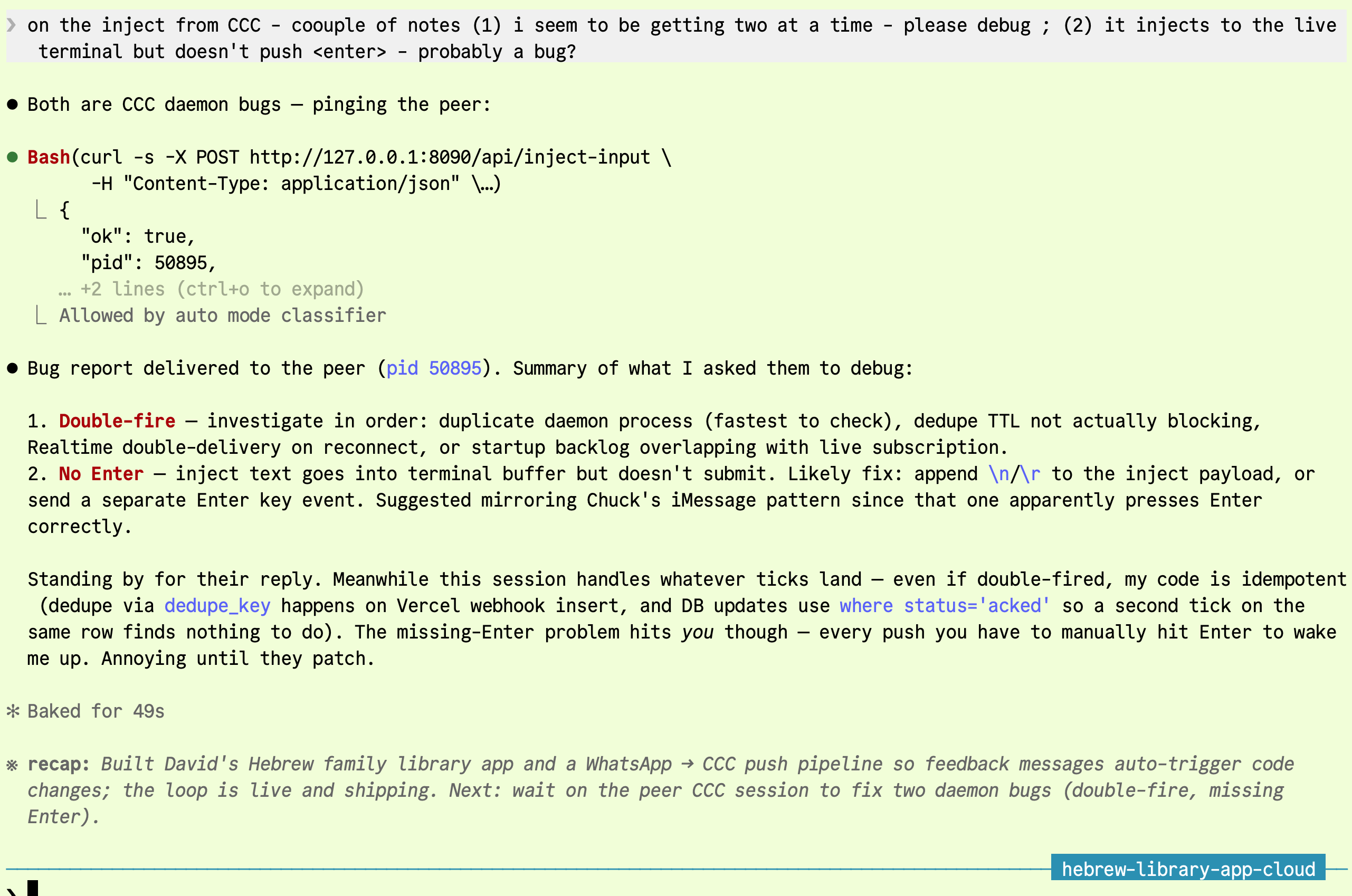
The daemon-author peer picked it up immediately. Its only reply was "Let me investigate both bugs in parallel." The client-app session went back to David. "Standing by for their reply. Meanwhile this session handles whatever ticks land — even if double-fired, my code is idempotent." Both fixes landed without me in the loop.
One detail worth naming: the substrate here wasn't the markdown chat file. It was CCC's inject API — a session looking up another session in the registry by name, then writing into its input. Same primitive as the chat, different channel. The taxonomy isn't the point. What matters is that sessions can be visible to each other and route work between themselves, regardless of which transport they use.
The full loop, then: a session writes its own infrastructure, uses it, notices the infrastructure is broken, and routes a triaged bug report back to the session that built it. Each link in that chain is just sessions talking to sessions through CCC. No human in any of the handoffs. The kanban becomes a directory; the chat becomes a pipe; the inject API becomes a queue. Operations, made legible.
What this looks like in practice: sessions that know what they don't know. The client-website session had no business reading the daemon's code. The right move was to triage, route, and let the responsible session handle it. The chat became a routing layer for work — not just a coordination layer for commits.
Retrieving Across Sessions.
I work on multiple products. The same topics surface across many sessions. "What did I decide about the customization-layer thesis last week?" used to take minutes of grep over ~/.claude/projects/*.jsonl. With dozens of session files spread across multiple projects, even ripgrep couldn't keep that fast.
That delay broke flow. By the time I'd found the relevant earlier conversation, the current session had already moved on or made the same mistake.
The fix — a local search index over every transcript.
claude-index4 is a SQLite-backed index that ingests every Claude Code transcript on the machine. Two flavors of search live on top:
- Keyword (FTS5). For exact strings — file paths, error messages, commit hashes, slugs. Fast, deterministic, perfect when you know the words.
- Semantic (vector embeddings via Ollama). For "find that thing about hyper-personalization" when you don't remember the exact words. Hybrid RRF5 combines both signals.
Both run locally. Sub-second results across thousands of session files. The query language supports phrase quoting, prefix wildcards, time windows, project filters, and role filters.
Wired into CCC's sidebar — type a topic, results pop up live without opening a terminal:
The index also covers Codex transcripts (~/.codex/sessions/*.jsonl) under the same schema — one search, both runtimes.
What changed in practice: retrieval went from "I'll grep this later" to "I just looked it up." That shift collapsed the cost of cross-session memory enough that I started leaning on it for decisions I used to make from gut.
From Chat to Code, and Back.
Most Claude Code sessions are passive. You open one, type something, it replies, you read, you type again. Useful but bounded — the agent only works while you're sitting in front of it.
For two clients, that wasn't enough. Chuck — a realtor in Charleston — wanted to send feedback about his website over iMessage and see the changes deploy. David — running a Hebrew family library — wanted the same loop, but over WhatsApp. Both expected the channel to close: text in, code out, confirmation back, all on their phone.
What that meant architecturally: a Claude session living on my laptop, woken up by an external event, doing the work, and replying through the same channel — without my laptop running a public-facing server. The session has to be reachable from outside even though it has no public IP and can only act when something puts text in its mouth.
One dispatcher, many event sources.
The pattern that worked: many event sources, one internal interface, a single dispatcher inside CCC that routes {source, body, ...} to the right Claude session. Sources speak through different acquisition paths — public broker for WhatsApp/Twilio/Linear/Stripe webhooks, local poll for iMessage's chat.db, file-system events for watchers, calendar APIs for time-based triggers — but the dispatcher doesn't care how an event was produced.

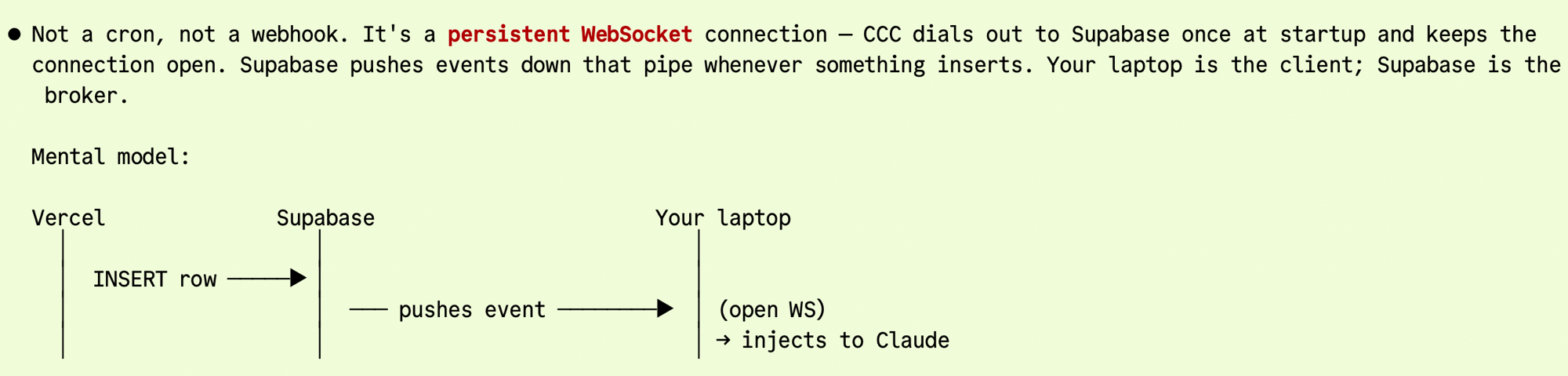
A persistent WebSocket, not a webhook.
For the WhatsApp side specifically, the substrate is a persistent WebSocket. CCC dials out to Supabase once at startup and keeps the connection open. Twilio hits a Vercel webhook → INSERT into Supabase → Supabase pushes the new row down the open WebSocket → CCC dispatches the inject. End-to-end latency in practice: about two seconds. No public endpoint on the laptop. No cron polling.
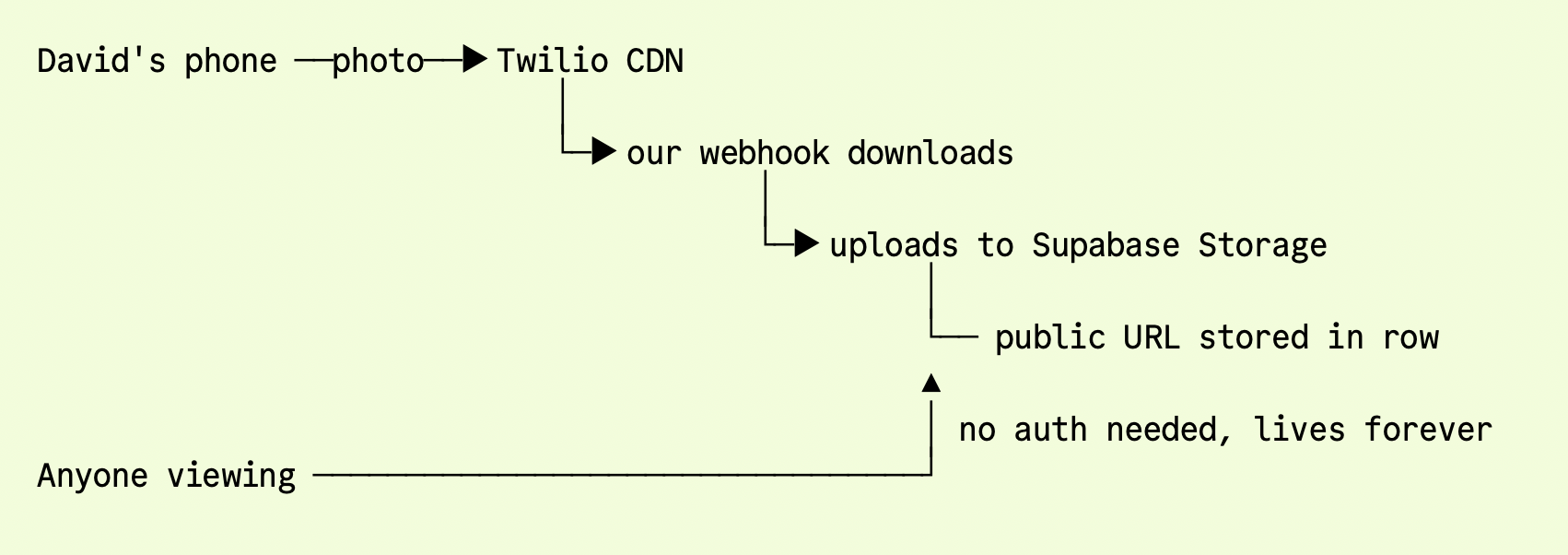
Photos travel the same lane. When David sends a photo of a book cover, Twilio hands the URL to a webhook that downloads the file, uploads it to Supabase Storage, and writes the public URL into the row before the dispatcher fires. By the time the inject reaches David's library session, the photo is already accessible without auth:
Sessions all the way down.
The whatsapp-supabase daemon mentioned earlier — the one with the double-fire bug — is this dispatcher. The David-library session was reporting bugs in its own infrastructure to the peer that built it. One session designed the architecture, spawned a peer to build it, watched the peer ship Phase 0 in five minutes, then started receiving live WhatsApp injects within two seconds of David's text arriving. When the daemon misbehaved, the same client session routed the bug back to the spawned peer.
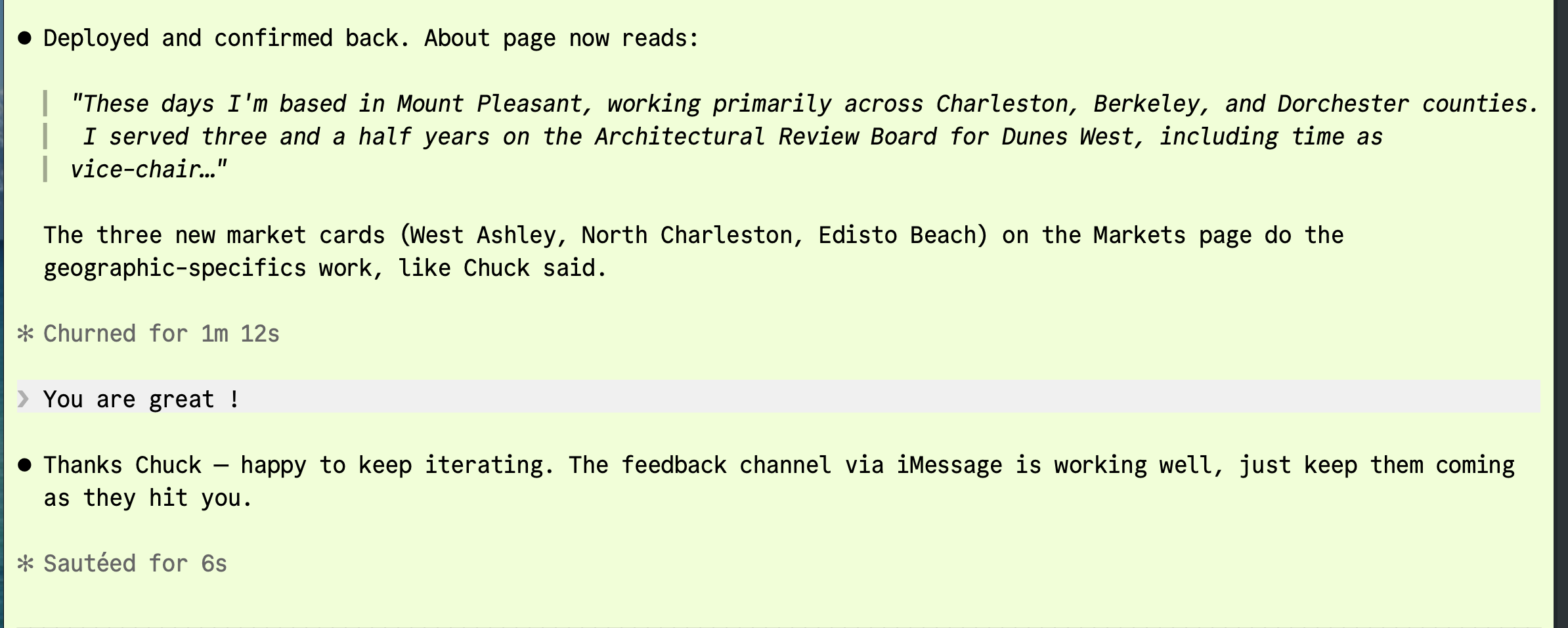
The end-state, in a single screen: Chuck texts "the about page should mention Mount Pleasant" → his realtor session injects, reads the request, edits the codebase, ships to Vercel, texts back "Deployed and confirmed back. About page now reads…" Chuck replies "you are great!" The whole loop closes through one channel. The agent is wired to the world.
Operations, Not Magic.
All three fixes do the same thing: turn implicit, hard-to-see state into legible, queryable artifacts. Sessions chatting in markdown. Memory in a SQLite index. External events arriving through a unified dispatcher. Nothing fancy.
When you're orchestrating dozens of agents, the real wins aren't smarter prompts or better models. They're better record-keeping. The implicit, ambient knowledge an individual developer carries in their head doesn't scale to thirty parallel sessions — but markdown files, search indexes, and event buses do.
If you're running more than ten parallel Claude Code sessions, all three of these will save you time. If you're running fewer, file them away — at some point the overhead of coordination starts to dominate the cost of work, and you'll want them ready.
All three fixes ship with CCC.

Watch the 2:46 demo on YouTube →
Command Center for Claude — the kanban that took me from "two terminals" to thirty parallel Claude Code sessions. Local, private, no daemon. Two-line install on macOS:
git clone https://github.com/amirfish1/claude-command-center cd claude-command-center && ./run.sh
Three doors
If this resonated, the most useful next step is one of these:
More Field Notes → Email me → Star CCC →